

In this article, we examine the way a FAT file system allocates a file. As the file allocation operation in FAT32 and other fat file systems is the same, we present the way a file is allocated in a generic way and then mention the specific extra notes at the end. Let’s now see how the FAT file system allocates a file using a detailed example.
Table of Contents

FAT Initial Configurations
In this example, the cluster size of the FAT file system is 4096 bytes.
- The cluster size is the unit of allocation in the FAT file system [1].
As the size of the FAT allocation unit is 4096 bytes, we can allocate 4096 bytes at a time. Any allocation request exceeding the cluster size will require multiple disk cluster allocations.
In case the size of the data to be saved is an exact multiple of the cluster size, then all the clusters will be fully utilized once they are allocated to store the user data.
However, in most cases, there will be some data left over that will not fill a full cluster. As the leftover data also need to be stored, another cluster has to be allocated. But, the cluster will have unused spaces or slack space in file system terminology.
FAT Table Initial State
As we know, the FAT file system has a table which stores a linked list of cluster numbers associated with a file.
For example, the following table shows 3 entries of a fat table.
- The index numbers 40, 41 and 42.
- All of these indexes have the associated value of 0 in the FAT table.
| Index | Value |
| 40 | 0 |
| 41 | 0 |
| 42 | 0 |
The interpretation of the shown FAT table state is that the disk clusters numbered 40, 41 and 42 are not currently allocated.
How do we know these clusters are not yet allocated?
- As the associated fat table entries have the value of 0.
In essence, when we would like to know whether a cluster is allocated, we check the index of the FAT table and see whether the value is 0 or not.
FAT Fsinfo Initial State
The FAT file system has a data structure called FSINFO.
The main utility of the FSINFO structure is that it helps the FAT file system find the next free cluster number and the free cluster count on the disk.
As the initial state of this example, the next free cluster in FAT is 40.
As a side note, the FSINFO structure may not always be up to date as the standard does not enforce it.
- Just think of the next free cluster number here as a hint to start the search for a free cluster.
- In case the cluster number pointed by the FSINFO is already allocated, we will check the 41 and keep incrementing the cluster number until we find a free cluster or we may also decrement it and check to see if any one of them has become free because of some deallocation happened.
Allocation Request
As part of the example, the FAT file system has received a call to store 6,000 bytes of data inside of a newly allocated file.
Disk Space Calculation
To better understand the disk space allocation stage, it is best to review first the disk space calculation that will be done as part of the allocation stage.
In this example, the data to be stored on disk is 6000 bytes. As part of disk calculation, we need to calculate the number of clusters to be allocated by the FAT file system.
Here the calculation simple because the data size 6000 bytes requires only 2 clusters as the cluster size is 4096 bytes.
- The first cluster will be full.
- The first 4096 bytes of the data will be stored inside the first cluster.
- Then, the file system will realize it still needs to store 1904 leftover data.
- As the requested 6000 bytes of data minus 4096 bytes stored data is 1904.
- Therefore, another cluster has to be allocated for the last 1904 bytes of data.
- The second cluster will have slack space.
- The remaining 1904 bytes of the data are stored inside the second cluster.
- The size of the slack space inside of the second cluster is 2192 bytes.
- As the cluster size, 4096 bytes, minus 1904 bytes results in 2192.
Therefore, the FAT file system with 4096 bytes of cluster size needs to allocate 2 clusters for the storage of 6000 bytes of data.
- The new file will cost 8192 bytes of disk data capacity.
- The length of the file will be 6000 bytes.
- The slack space of the file is 2192 bytes.
Disk Space Allocation
As part of the disk space calculations, it has been found that 2 new clusters need to be allocated for the new file.
Since the allocation status of the disk clusters has been stored inside of the FAT table, when allocating disk space, the associated FAT table entry values are checked.
Disk Space First Cluster Allocation
Using the FSINFO structure, it has been found that the next free cluster number is 40.
When the FAT table row 40 value is fetched from the disk, it has been found that it has a value of zero.
As the zero value of a fat table entry shows that it is free to be allocated, it is allocated by putting the value EOF into the fat table.
- EOF stands for End of File.
In FAT, the special EOF value is given to the last cluster of a file. Since the file currently has only one allocated cluster, it is the last cluster of the file and has the special EOF value insde of the FAT table.
Interpretation of FAT Table State
| Index | Value |
| 40 | EOF |
| 41 | 0 |
| 42 | 0 |
The way we interpret the state of the FAT is as follows:
The FAT table entry 40 has a value non-zero value.
- Therefore, it is allocated.
But, the FAT table entry has special EOF value.
- Therefore, there is no next cluster for the file.
- Currently, the file has only one cluster as the value of the fat table entry says “End of File”.
Disk Space Second Cluster Allocation
After the allocation of the first disk cluster, still there exists data to store. Therefore, one more cluster will be allocated.
As the next free cluster is now 41 in the FAT table, it will also be allocated. But, the allocation of the second cluster differs from the way we allocate the first cluster.
Currently, the file has one allocated disk cluster.
- The starting cluster of the file is 40.
In the first phase of the file associated second cluster allocation, cluster 41 will be allocated just like the way we allocate the first cluster.
| Index | Value |
| 40 | EOF |
| 41 | EOF |
| 42 | 0 |
Then, cluster 41 will be marked as the continuation of cluster 40.
| Index | Value |
| 40 | 41 |
| 41 | EOF |
| 42 | 0 |
FAT Cluster Chains
The way we interpret the last state of the FAT table is as follows.
The file starts at cluster 40.
- As the FAT table entry has a value other than 0 we know it is allocated.
The second cluster of the FAT table is 41.
- The value of FAT table row 40 is 41.
Cluster 41 is the last cluster of the file.
- The value of FAT table row 41 is EOF.
Therefore, the file-associated cluster chain has 2 clusters.
| Cluster 40 | Cluster 41 | EOF |
The extra details of the FAT Cluster Chains can be found in the FAT Cluster Chain Article.
File Existence Control
As part of the call, it is specified that data will be stored inside a new file named “file1.dat” that resides inside an existing folder named “dir1”.
- Therefore, the path of the new file is “/dir1/file1.dat”.
Before any disk space allocation, when the call is made to the FAT file system, it will first check the existence of the file. In case the file already has disk space allocated to it, the disk space allocation step, described in the file disk allocation, will be omitted.
As part of the file search, we need to take the following steps in sequence:
- Find the FAT root directory.
- Find the ‘dir1’ directory entry inside the root directory.
- Find the ‘file1.dat’ directory entry inside the directory named as ‘dir1`.
Find FAT Root Directory
Finding the Root directory is a bit complex and out of context for this section. Therefore, we will only provide a summary here.
The information about the root directory is stored inside the first sector of the FAT file system.
- The first sector of the FAT is known as the boot sector.
From the boot sector, we obtain the cluster number of the root directory.
In this example, the root directory cluster number is 2.
Directory Clusters
Other than data clusters where we store the data of the file, there exist directory clusters. The directory clusters only store a set of directory entries. The directory entry data contains the metadata about the associated files or directories found inside of a directory.
Find Root Directory Entry
To find the ‘dir1’ inside of the root directory, the root directory cluster number is used. First, the content of the root directory cluster is read from the disk. Then, one by one, all directory entries are reviewed inside of the root directory.
As the ‘dir1’ already exists in the root directory, a directory entry which has the name ‘dir1’ is found. The ‘dir1’ associated cluster number is found as 90.
Find Root Sub-folder Directory Entry
Just like the way we search the root directory for the ‘dir1’ entry, we search the ‘dir1’ directory for the entry ‘file1.dat’.
The operation is as follows:
- Read the cluster 90.
- It contains the content of the ‘dir1’ directory.
- Iterate over each directory entry found in the dir1.
- If a directory entry with the name ‘file1.dat’ is detected, it means the file exists.
As the precondition of this example, ‘file1.dat’ does not exist in the ‘dir1’, the search operation will fail to the file.
File Allocation
The request was to save 6000 bytes of data into the ‘/dir1/file1.dat’ file. As the ‘file1.dat’ is not found in the ‘dir1’ directory, we need to create the file. As part of the previous sections, we have talked about the space allocation of the file. It is the time to make that set of operations.
As the file does not exist, we first need to allocate the file. For this purpose, first, we allocate the first cluster of the file and allocate a directory entry inside of the ‘dir1’ directory. Then, the second cluster of the file is also allocated and data is written to these clusters.
- Allocate the first cluster of the file.
- Cluster 200 is allocated to the file.
- Allocate file typed directory entry inside ‘/dir1’ directory.
- The directory entry stores the name of the file ‘file1.dat’ as well as the beginning cluster of the file which is 200.
- Write the first 4096 bytes of data to the first cluster(cluster 200).
- Allocate the second cluster.
- Cluster 201 is allocated and inserted into the file cluster chain.
- Write the remaining 1904 bytes of data to the second cluster(cluster 201).
File Data Write
As we know, the FAT table stores the allocation states of the data clusters. After a cluster is allocated to a file, the file data can be written freely to the associated data clusters.
In this example, the first cluster of the file is 200.
- When the FAT table is checked, it is seen that the file has allocated the cluster 200.
- While the details are to be ignored here, the disk data cluster at the index 200 is modified by the fat write operation.
Then, the remaining 1904 bytes of data written also modify the associated cluster 201.
- But, different from the full cluster write, only the first 1904 bytes of the cluster are written.
Directory Entry Allocation
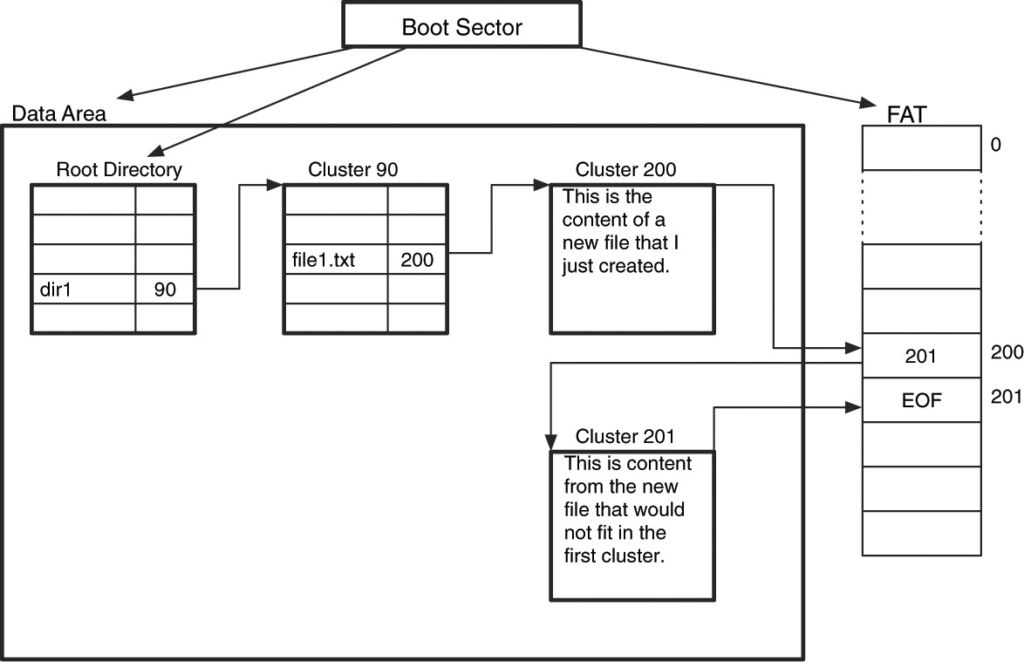
- We read the boot sector from sector 0 of the volume and locate the FAT structures, data area, and root directory.
- We need to find the dir1 directory, so we process each directory entry in the root directory and look for one that has dir1 as its name and the directory attribute set. We find the entry, and it has a starting cluster of 90.
- We read the contents of dir1’s starting cluster, cluster 90, and process each directory entry in it until we find one that is unallocated.
- We find an available entry and set its allocation status by writing the name file1.txt. The size and current time are also written to the appropriate fields.
- We need to allocate clusters for the content, so we search the FAT structure. We allocate cluster 200 for the file by setting its entry to the EOF value.
- We write the address of cluster 200 in the starting cluster field of the directory entry. The first 4,096 bytes of the file content are written to the cluster. There are 1,904 bytes left, so a second cluster is needed.
- We search the FAT structure for another cluster and allocate cluster 201.
- The FAT entry for the first cluster, cluster 200, is changed so that it contains 201. The last 1,904 bytes of the file are written to cluster 201.
Allocation Mechanism
The data storage of the new file named “dir1/file1.dat” has been shown in the last section in detail.
Search File Existence
Allocate Clusters
The clusters are allocated one by one.
As part of the example, we assumed that the FAT uses first available next cluster. But, there are other algorithms.
- Allocate cluster by starting the search from the start of FAT table.
- Allocate cluster from the closest fat table entry.
- Allocate clusters by calculating the physical distance between the cluster associated disk addresses.
The way we allocate the next clusters of a file(other than starting cluster) is implementation defined. Here, for the purpose of simplicity we have chosen two staged allocation scheme. This scheme plays safe and in case of a crash, there will be only an orphan file cluster allocated. But, the file will not be corrupted. Some other mechanisms also possible.
Clean/Dirty state of a newly allocated cluster data area.
The logical block address of the cluster number is….
References
https://learning.oreilly.com/library/view/file-system-forensic/0321268172/ch09.html#ch09lev1sec1
[2] Microsoft FAT32 Standard Documentation